DDoS Attack Prevention: Comprehensive Enterprise Network Protection with ShieldWatch XDR
DDoS (distributed denial of service) attacks are coordinated efforts to overwhelm network, application, or protocol resources so legitimate users can’t reach critical services. They threaten availability, revenue, and regulatory compliance. This guide shows how organizations classify, detect, and mitigate modern DDoS campaigns and outlines practical defense layers that strengthen resilience and operational readiness.
You’ll learn the main attack types, how XDR platforms correlate cross-domain telemetry to uncover distributed campaigns, the role of AI and SOAR in automated containment, why 24/7 managed SOC capabilities matter, and pragmatic incident response playbooks. We present vendor-agnostic best practices while illustrating how an enterprise XDR plus managed SOC approach shortens time-to-detect and time-to-contain, using ShieldWatch XDR as a concrete example of unified detection, agentic AI, hyper-automation, and human-led operations hardening networks against DDoS threats.
What Are the Primary Types of DDoS Attacks and Their Impact?

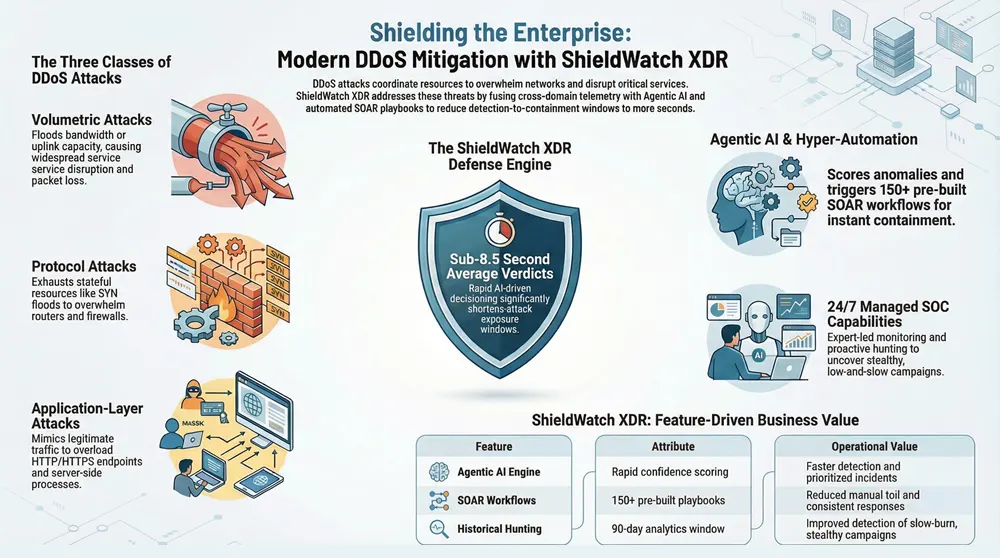
DDoS campaigns typically fall into three classes—volumetric, protocol, and application-layer—each targeting different parts of the stack and producing distinct operational effects. Volumetric attacks flood bandwidth, protocol attacks exhaust connection state or device resources, and application-layer attacks overload server-side application processes while often appearing as legitimate traffic. Each class reduces availability by different means and requires targeted telemetry for reliable detection. In 2024 attackers increasingly blend vectors to evade single-layer defenses, so defenders should instrument network, application, and endpoint telemetry to build robust detection and response. The next section breaks down the technical differences and what they imply for mitigation.
Volumetric / protocol / application distinctions and one-line impacts:
- Volumetric DDoS: saturates bandwidth or uplink capacity, causing widespread service disruption and packet loss.
- Protocol DDoS: exhausts stateful protocol resources (for example, SYN floods), degrading device performance and connection handling.
- Application-layer DDoS: targets HTTP/HTTPS endpoints or APIs, exhausting server resources while mimicking legitimate users.
This classification helps security teams prioritize telemetry collection and pick mitigation tactics that match the attack signature and business impact.
How Do Volumetric, Protocol, and Application Layer Attacks Differ?
Volumetric attacks push large traffic volumes—UDP floods, amplification, or botnet-driven streams—making them visible in aggregate telemetry such as packets-per-second and sustained throughput. Protocol attacks abuse protocol state (SYN/ACK handshakes, fragmented packets) to overwhelm routers or firewalls and are detectable through anomalous session metrics and malformed packet patterns. Application-layer attacks imitate legitimate user behavior against web servers or APIs (for example, slow POSTs or bursty GETs) and require deep application telemetry and behavior baselines to separate malicious activity from real demand. Recognizing these signals guides the choice of mitigations: traffic scrubbing, rate limiting, connection throttling, or application-layer WAF rules.
What Are the Emerging DDoS Attack Vectors in 2024?
In 2024 attackers increasingly combine encrypted HTTPS floods, DNS-layer surges, and commoditized IoT/botnet orchestration to increase scale and stealth—making signature-based detection less effective. They favor encrypted and low-and-slow patterns that resemble legitimate sessions, forcing defenders to rely on richer telemetry—TLS fingerprints, session timing, and device reputation—to distinguish malicious traffic. Ransom-driven DDoS and multi-vector campaigns that mix reflection/amplification with application targeting are common, underscoring the need for layered defenses and fast coordination with network providers. Because these vectors exploit telemetry gaps across environments, the next section explains how XDR platforms fuse cross-domain signals to raise detection fidelity.
How Does ShieldWatch XDR Enhance DDoS Mitigation Through AI and Automation?
ShieldWatch XDR strengthens DDoS defenses by correlating telemetry from endpoints, network devices, cloud services, and identity sources to reveal distributed campaigns that single-signal tools miss. Cross-domain correlation produces context-rich incidents where AI assigns confidence scores and SOAR playbooks automate containment, shortening the detection-to-response loop and cutting manual toil. Agentic detection engines surface anomalous traffic patterns while automation executes mitigations—rate limits, ACL updates, or traffic redirection—so teams can focus on escalations that need human judgment. Below are the practical mechanisms by which XDR and automation improve DDoS outcomes.
- Telemetry correlation across network, endpoint, and cloud sources to expose distributed attack patterns.
- AI-driven anomaly detection that assigns verdicts and reduces false positives.
- SOAR-driven playbooks that automate containment actions and stakeholder notifications.
Together these mechanisms reduce blind spots and mean time to contain; the following subsections describe agentic AI and hyper-automation in more detail.
What Role Does Agentic AI Play in Real-Time Threat Detection?
Agentic AI functions as an autonomous detection and decision layer that ingests streaming telemetry, scores anomalies, and recommends or triggers containment when confidence thresholds are met. By synthesizing packet-level anomalies, session behaviors, and identity signals, agentic AI uncovers coordinated DDoS patterns faster than static rules and helps prioritize high-confidence incidents. This reduces noisy alerts by directing analyst attention to incidents with cross-domain corroboration and supports a human-in-the-loop model where analysts validate sensitive actions. The typical path from anomaly to verdict involves signal enrichment, scoring, and either automated remediation or analyst review based on policy and impact.
How Does Hyper-Automation Enable Rapid Incident Response?
Hyper-automation uses SOAR workflows and pre-built playbooks to run containment actions as soon as a trusted verdict is issued, cutting manual steps and MTTR. Typical automated responses include temporary rate limiting, ACL updates, initiating traffic scrubbing, and notifying network operations and upstream providers—all while capturing forensic telemetry for after-action review. Safeguards such as escalation gates, rollback steps, and staged automation prevent overreach and let analysts pause or refine flows to preserve service continuity. With policy-driven automation, containment shifts from hours to a human-validated sequence that completes within operationally relevant windows.
Why Are Managed SOC Services Essential for 24/7 DDoS Protection?
Managed SOC services provide continuous, expert monitoring and proactive hunting that reduce blind spots and detection latency—critical because DDoS campaigns often occur outside business hours and can escalate quickly. Human oversight complements automated detection by validating complex multi-vector campaigns, coordinating with network operators, and executing containment when escalation requires analyst judgment. Managed SOC teams also maintain institutionalized playbooks and threat-hunting routines that surface slow-burn campaigns and evolving botnet indicators before they peak. The next sections show how continuous monitoring and expert response lower operational risk and speed recovery.
- 24/7 monitoring reduces detection latency and helps maintain service availability around the clock.
- Proactive threat hunting uncovers stealthy multi-vector campaigns and IoT/botnet activity.
- Analyst-led coordination accelerates containment and communication with external providers.
These capabilities augment internal teams and are particularly valuable for mid-market enterprises and MSP partners that need reliable, continuous defense.
How Does Continuous Monitoring and Threat Hunting Reduce Risk?
Continuous monitoring consolidates telemetry and applies behavioral baselines to spot deviations that signal emerging DDoS activity, enabling detection earlier than at the point of service failure. Threat hunting reviews extended historical windows to find recurring indicators, lateral patterns, or botnet reuse; longer analysis windows reveal slow, stealthy campaigns that evade short-term detectors. Historical context and enriched telemetry let analysts tune detections and automate repeatable containment, lowering false negatives and easing triage workload. Combining always-on monitoring with periodic hunting closes detection gaps and raises assurance of service continuity.
What Are the Benefits of Expert-Led Incident Response for DDoS?
Expert-led response delivers prioritized triage, clear stakeholder communication, and forensic rigor that shorten downtime and improve post-incident remediation. Analysts coordinate automated and manual containment steps while liaising with network operations and upstream providers for reroutes or scrubbing when needed. After an attack, experts perform root cause analysis, document timelines, and recommend configuration and architectural hardening to prevent recurrence. This mix of speed and institutional learning raises organizational readiness and reduces the chance and impact of repeat incidents.
Which Key Features of ShieldWatch XDR Build Unmatched Network Resilience?
This section maps ShieldWatch XDR capabilities to resilience outcomes that matter to CIOs and CISOs evaluating DDoS protection. The table below links platform attributes to operational value, showing how specific features translate into measurable benefits like reduced MTTR, fewer false positives, and stronger compliance posture.
How Do Sub-8.5 Second Verdicts and SOAR Workflows Accelerate Containment?
A low-latency verdict engine flags high-confidence incidents and can trigger predefined SOAR workflows that automate containment tasks, shrinking the time between detection and action to operationally meaningful levels. For example, rapid verdicting can initiate rate limits, update ACLs, or invoke traffic scrubbing playbooks while logging actions for audit and rollback. The EAV table below ties automation steps to outcomes so teams can map decisions to measurable results.
In What Ways Does ShieldWatch Reduce Alert Fatigue for Security Teams?
ShieldWatch reduces noise by correlating signals across domains, applying ML suppression for low-confidence events, and enriching alerts with context so analysts can decide faster. Context-rich incidents include source telemetry, impact assessments, and recommended playbooks, which let teams resolve many issues without long investigations. Automated remediation for routine or low-risk alerts removes repetitive tasks from human queues and frees analysts to focus on complex multi-vector attacks. Together, these features improve signal-to-noise and create capacity for proactive security engineering.
How Does ShieldWatch Support Compliance and Reporting for DDoS Incidents?

Organizations must show control over availability and incident response. ShieldWatch helps by producing forensic artifacts, timelines, and evidence aligned with common compliance standards and audit requirements. Continuous monitoring, historical telemetry retention, and standardized incident reports create the documentation auditors expect after DDoS events. The table below maps standards to the types of evidence ShieldWatch can produce and retain for investigations and audits.
What Are the Relevant Standards: SOC 2, HIPAA, CMMC 2.0, ISO 27001?
Each standard stresses availability, incident response, and evidence retention in different ways. SOC 2 focuses on control effectiveness and clear incident timelines; HIPAA emphasizes availability and breach response for protected health information; CMMC targets cybersecurity practices and proof of event handling for defense suppliers; ISO 27001 requires documented incident management and continual improvement. ShieldWatch’s artifacts—detailed logs, playbook execution records, and enriched incident summaries—help organizations assemble the documentation auditors and assessors expect.
How Does Continuous Monitoring Facilitate Audit and Regulatory Requirements?
Continuous monitoring builds a searchable, time-stamped repository of telemetry and incident artifacts auditors use to validate controls and incident handling. Retained historical data supports retrospective trend analysis, validation of mitigation effectiveness, and reconstruction of incident timelines during investigations. Searchable logs and standardized reports speed evidence collection and reduce the overhead of ad hoc data pulls. This audit-ready posture not only supports compliance but also drives continuous security improvement.
What Are the Best Practices for DDoS Incident Response and Recovery with ShieldWatch?
A clear incident response playbook reduces decision latency and ensures repeatable recovery. Adopt a staged approach: triage, contain, remediate, and analyze. Triage validates the alert, scopes affected systems, and notifies stakeholders; containment runs automated or manual mitigations to preserve service; remediation fixes root causes and hardens systems; post-incident analysis turns findings into practical improvements. The numbered playbook below is an operational sequence security teams can follow during DDoS events.
- Triage: Validate the alert, gather telemetry, and determine scope and impact.
- Mobilize: Notify network operations, the CSIRT, and external providers as required.
- Contain: Run automated playbooks (rate-limiting, ACLs, scrubbing) or apply manual mitigations.
- Stabilize: Monitor post-action telemetry to confirm traffic normalization.
- Remediate: Patch exploited vectors, tighten access controls, and update WAF rules.
- Communicate: Provide timely updates to stakeholders and affected customers.
- Analyze: Conduct an after-action review, update playbooks, and implement long-term fixes.
Following this sequence keeps responses clear under pressure and enables measurable gains in readiness and MTTR. The next subsections translate these steps into concrete triage and post-incident activities.
What Are the Steps for Effective Triage, Containment, and Remediation?
Effective triage starts with rapid validation: correlate network and application logs, confirm service impact, and rule out configuration changes or benign traffic spikes. Containment depends on scope—automated SOAR playbooks can apply temporary rate limits or ACL updates for volumetric attacks, while application-layer incidents may need targeted WAF rules or traffic shaping. Remediation addresses root causes such as exposed APIs, insufficient rate limits, or misconfigurations and includes patching, capacity planning, and operational hardening. Record actions and timestamps at every phase to support post-incident analysis and compliance evidence.
These structured steps move teams from chaotic detection to repeatable recovery with measurable results.
How Is Post-Incident Analysis Conducted to Strengthen Future Defense?
Post-incident analysis combines forensic review, root-cause identification, and lessons-learned that translate findings into new detection rules and SOAR playbooks. Analysts review captured telemetry, evaluate which mitigations succeeded, quantify MTTR improvements, and spot coverage or communication gaps. Results feed back into agentic AI tuning, playbook updates, and remediation priorities such as capacity upgrades or application hardening. Tracking metrics—reduced MTTR, fewer repeat incidents, and improved detection precision—demonstrates continuous improvement and supports executive risk reporting.
This operational loop—detect, respond, analyze, harden—raises network resilience over time while keeping audit artifacts and improvement roadmaps aligned with compliance requirements.
Frequently Asked Questions
Conclusion
Strong DDoS prevention is essential to protect availability and business continuity. ShieldWatch XDR—combined with automated playbooks and 24/7 managed SOC capabilities—helps organizations detect distributed campaigns faster, contain them reliably, and preserve audit-ready evidence for compliance. By blending AI, automation, and human expertise, you lower downtime, reduce operational risk, and strengthen long-term resilience. To fortify your network, explore ShieldWatch’s DDoS protection capabilities and operational playbooks today.
Have you ever considered publishing an ebook or guest authoring on other blogs?
I have a blog centered on the same ideas you discuss and would really like to have you share some stories/information. I know my audience would value your
work. If you’re even remotely interested, feel free to shoot me an email.
https://shorturl.fm/shXw1
https://shorturl.fm/zOmRS
https://shorturl.fm/D3olr
https://shorturl.fm/mhRta
https://shorturl.fm/YmGmI
https://shorturl.fm/RszcR
https://shorturl.fm/GlmnS
https://shorturl.fm/OFnTN
https://shorturl.fm/81AOn
https://shorturl.fm/U0htm
https://shorturl.fm/hi0PK
https://shorturl.fm/tpBoX
https://shorturl.fm/ux7Yk
https://shorturl.fm/afhCb
https://shorturl.fm/JbSY9
https://shorturl.fm/VpTe8
https://shorturl.fm/cEdzh
https://shorturl.fm/fawXR
https://shorturl.fm/8EvMe
https://shorturl.fm/MmNPU
https://shorturl.fm/MKhPR
https://shorturl.fm/LdprK
https://shorturl.fm/tYZEr
https://shorturl.fm/3hwg3
https://shorturl.fm/C7JwQ
https://shorturl.fm/FuMk3
https://shorturl.fm/d7iNC
https://shorturl.fm/8Wfpq
https://shorturl.fm/PuJq2
https://shorturl.fm/9XjLf
https://shorturl.fm/QJluR
https://shorturl.fm/D3DWO
https://shorturl.fm/2814a
https://shorturl.fm/EoACc
https://shorturl.fm/mPbkp
https://shorturl.fm/0Ldtw
https://shorturl.fm/heqJ0
https://shorturl.fm/lJQxu
https://shorturl.fm/m73JM
https://shorturl.fm/oSOh9
https://shorturl.fm/aectx
https://shorturl.fm/sQ7Pe
https://shorturl.fm/acl5T
https://shorturl.fm/2oVlq
https://shorturl.fm/5pUhM
https://shorturl.fm/W6jSq
https://shorturl.fm/2E0hk
https://shorturl.fm/5EUt5
https://shorturl.fm/rQiQG
https://shorturl.fm/qXoa0